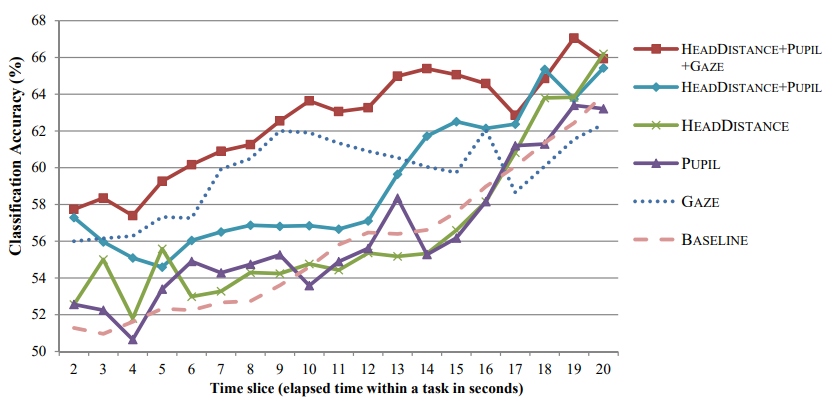
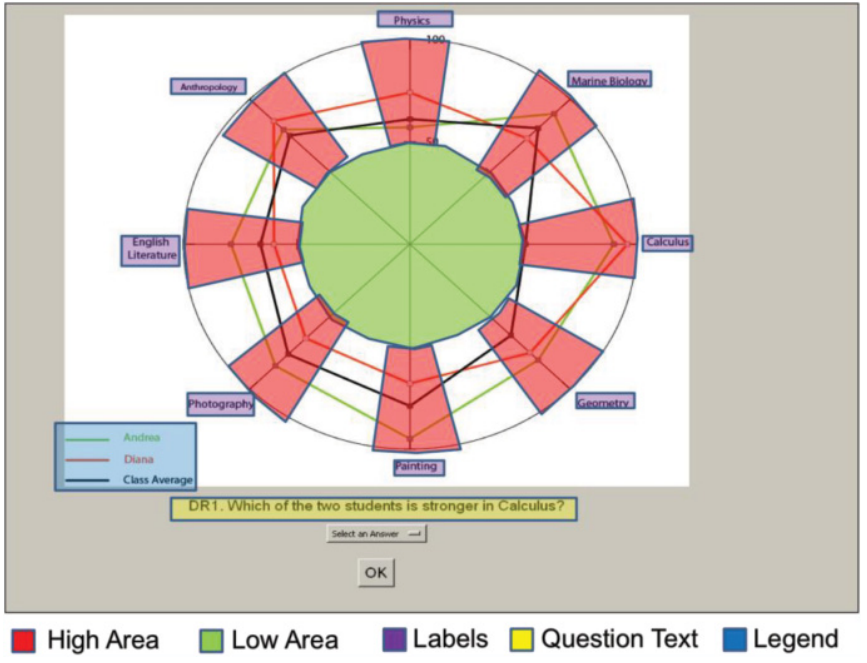
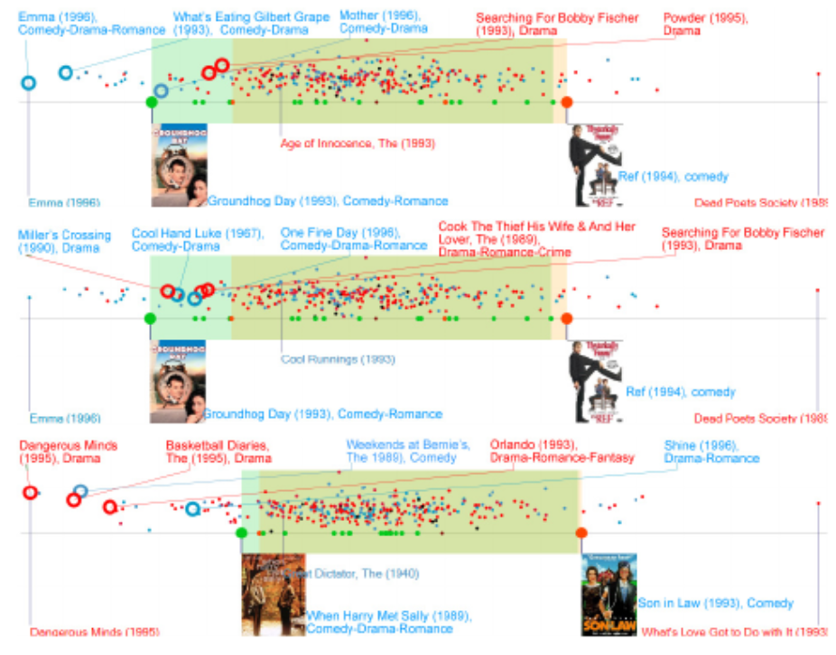
The most common technique for evaluating provenance
data is the use of classification and statistical modeling
techniques to differentiate sequences of user actions. The overarching goal of such
techniques is to
map a user action to one or more categories. A number of surveys in
the literature have demonstrated the application of these techniques
to a variety of data types relevant to provenance analysis, including
text and images. Indeed,
many of the common types of insights that users wish to identify in
data necessitate a classification phase, including comparison, correlation,
distribution, and trend insights. In this section, we
identify publications that classify provenance data into groups of
similar user actions via a variety of methods, ranging from straightforward
clustering through complex machine learning processes.